Question-Answering on data
Use LLMs to retrieve the best matching answer from knowledge sources
Ever wondered what if we could provide all the PDF files containing company rules and regulations as the background knowledge to a large language model such as GPT and have it as an agent to reply our queries? At Relevance, it is not a wonder anymore. We can actually build such an agent in the matter of minutes, even embed it to a websites.
What do we need
-
Data
Collect all sources of data that you want to provide the LLM as knowledge. Note that you are not limited to PDF when providing your knowledge. Even Audio/Video files (e.g. user guides) can be the knowledge source.
No need to worry about OCR or transcription. Relevance will automatically take care of such steps.
-
Tool configuration
Put together a Tool that
- receives knowledge
- receives question
- provides the best answer from the knowledge to the question
Let’s build a knowledge retrieval Tool
- Start with clicking on
+ Create toollocated on top right of the Tools page. For more information see how to create a tool. - Click on
+ Add dataon the knowledge section to add knowledge to your Tool. Note that you can upload knowledge sources to your Tool directly from the add knowledge window, or select already existing data tables on your accounts.
Make sure to enable knowledge (i.e. vectorize your data). Vectors allow semantic search (as opposed to word-matching) and increase the accuracy of knowledge retrieval.
- Add a text input component which will carry the query/question. Lets call
it
query. Your Tool must be similar to the image below.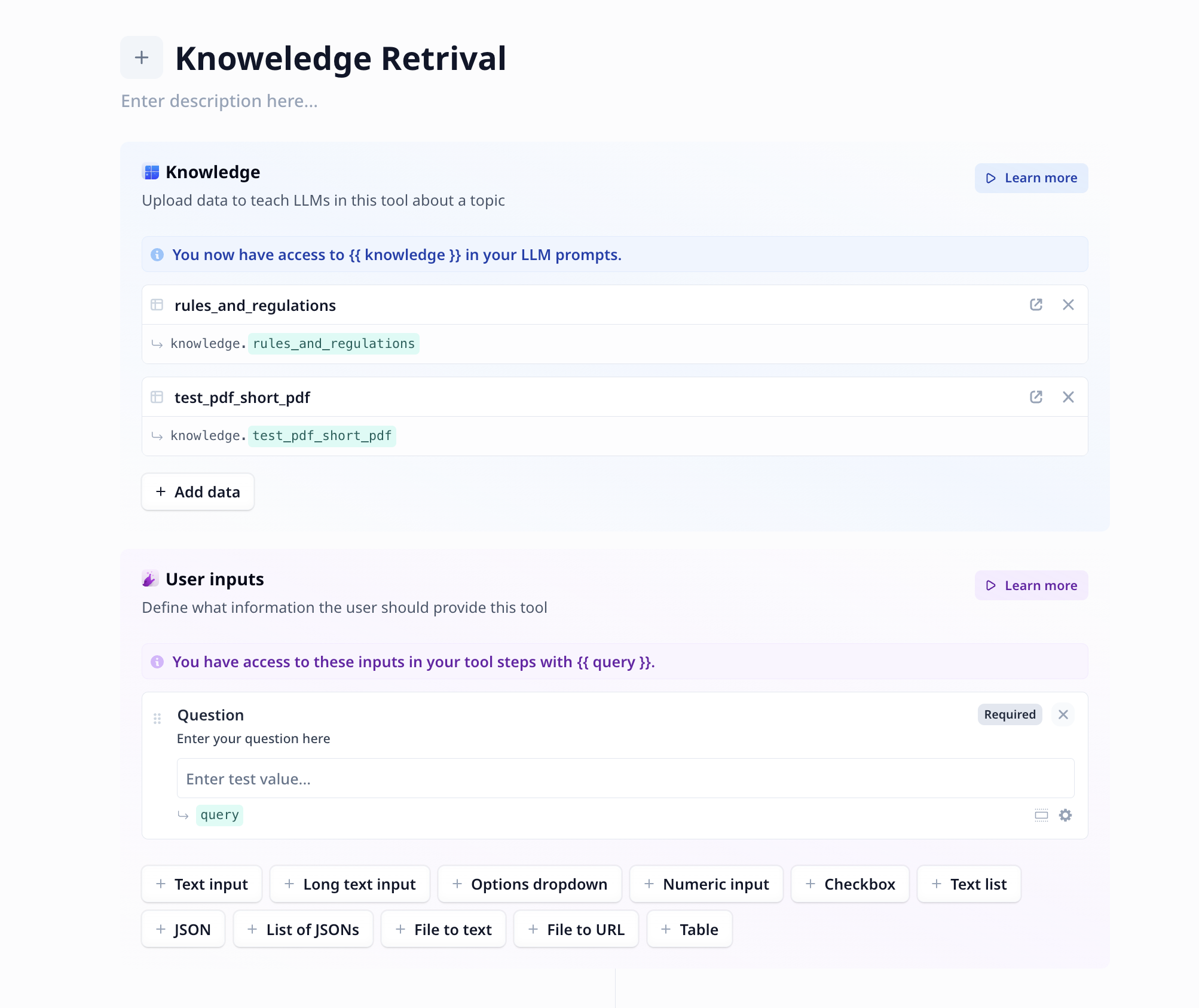
- Add an LLM component.
-
The prompt
Use
{{}}and the component names (i.e.knowledgeandqueryin our current example) to bring the knowledge and the question to the prompt. Provide precise instruction on what you need from the model. For example a very simple prompt could beContext: """ {{knowledge}} """ Goal: Use the above Context and nothing else and answer the question below. Question: {{query}} -
Handling large amount of data
We know that LLMs come with limitations on the number of tokens included in the prompt. Dealing with large amount of text such as rules and regulations, and trying to answer questions, we need to stick to most relevant data. Under LLM advanced options, under “How to handle too much content”, click on
Editlocated in front ofknowledge. By default we select most relevant data using vector search. But it is recommended to set it up manually.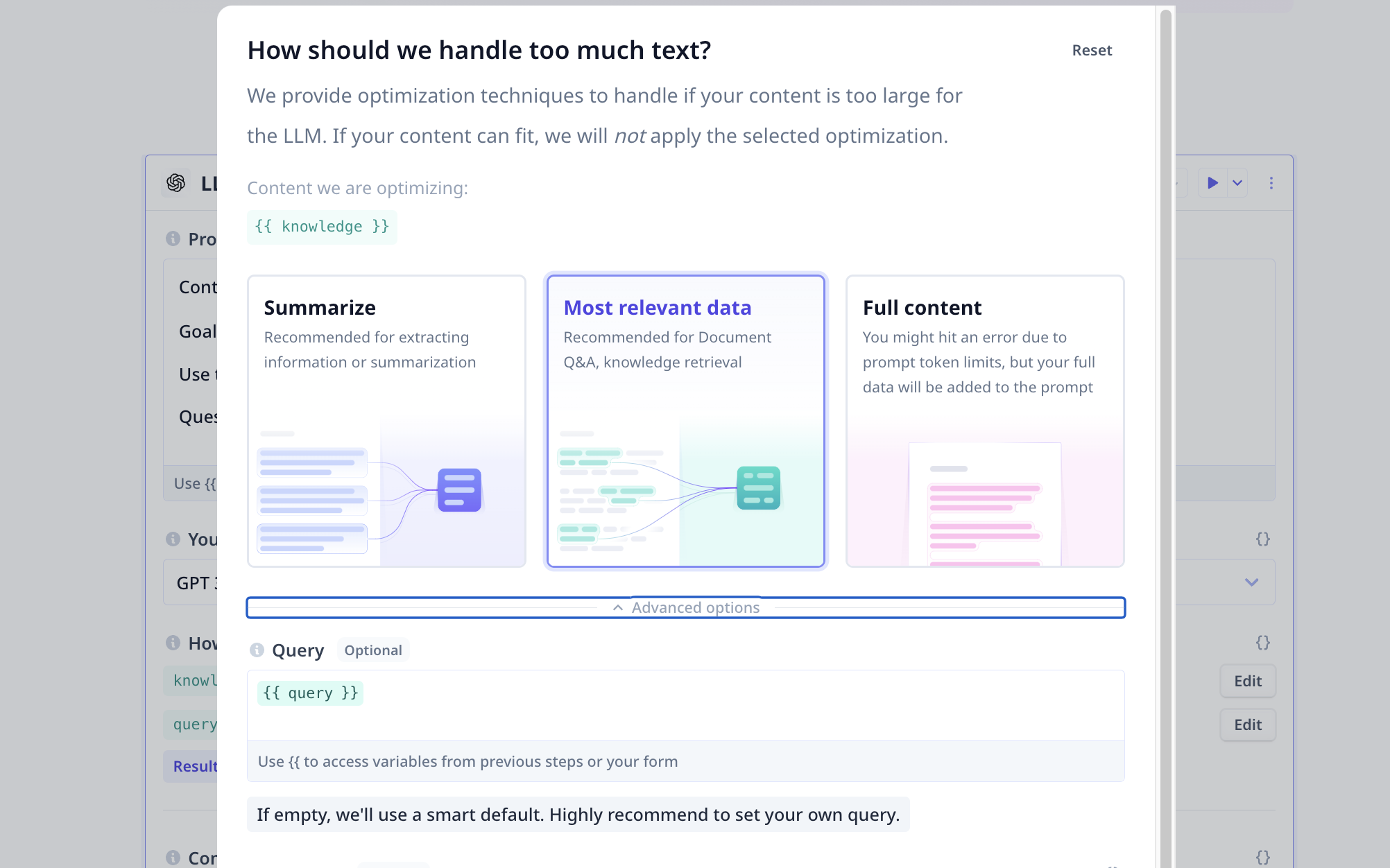 With
With Most relevant dataselected, click on “Advanced options” and type{{query}}(i.e. name of the component containing our question) to filter out any non-relevant information to the query. More details are provided at How to handle too much text. -
System prompt
Scroll further down and under “System prompt”, give some characteristics to your knowledge retrival agent. For instance:
You are an expert in rules and regulation in company XYZ. You will answer questions based on the provided knowledge and ...or
You are an expert in knowledge retrieval from large sources of data. You will answer questions precisely based on the provided knowledge. -
Output
Click on LLM output button (located on the top right of the component) if you wish to modify the output.
Answeris the main output, the rest provide you with information regarding the execution and can be safely deleted.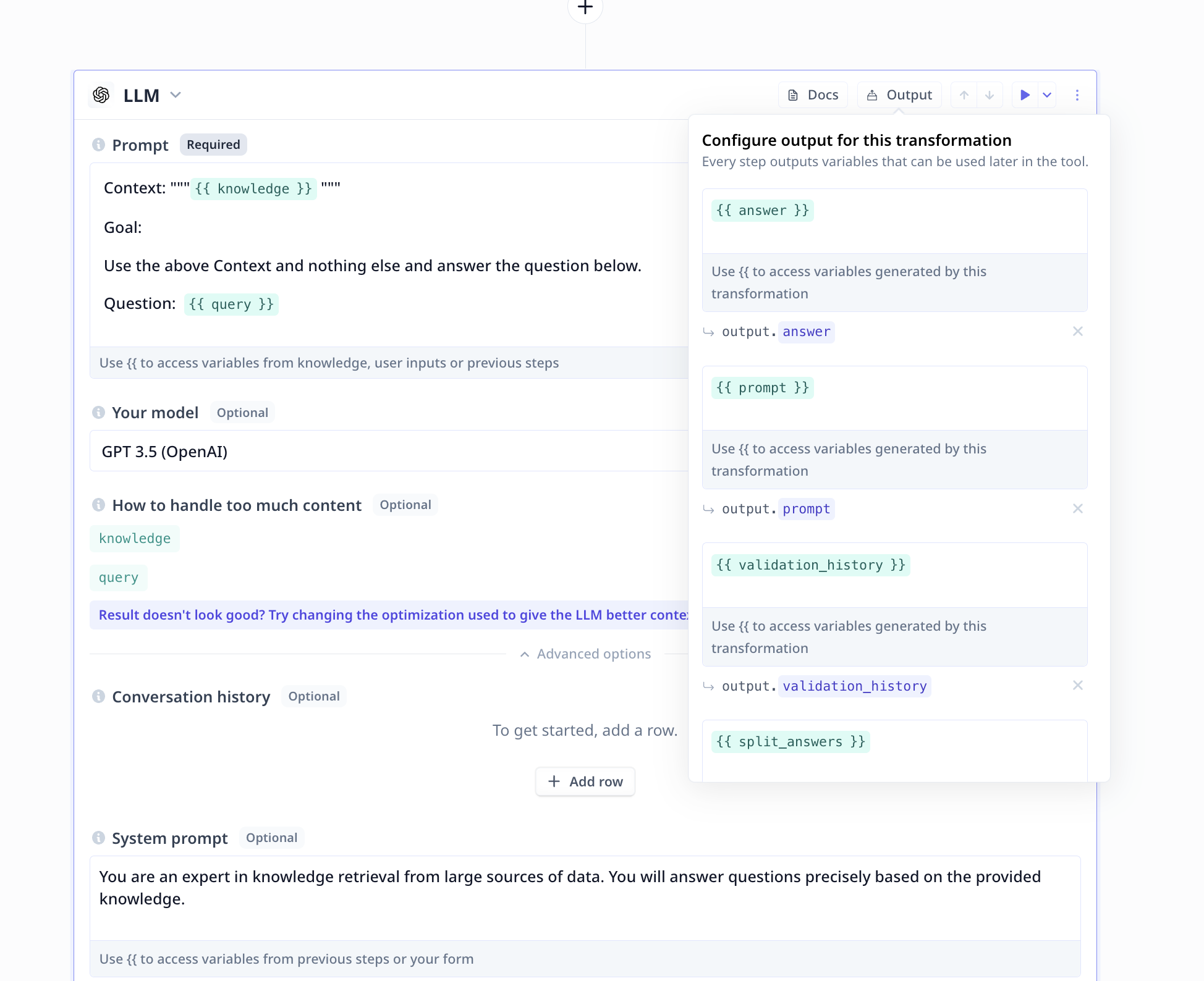
- Save the Tool using the button on the top right of the page and you are ready to enter your query and get responses from your knowledge retrieval large language model.
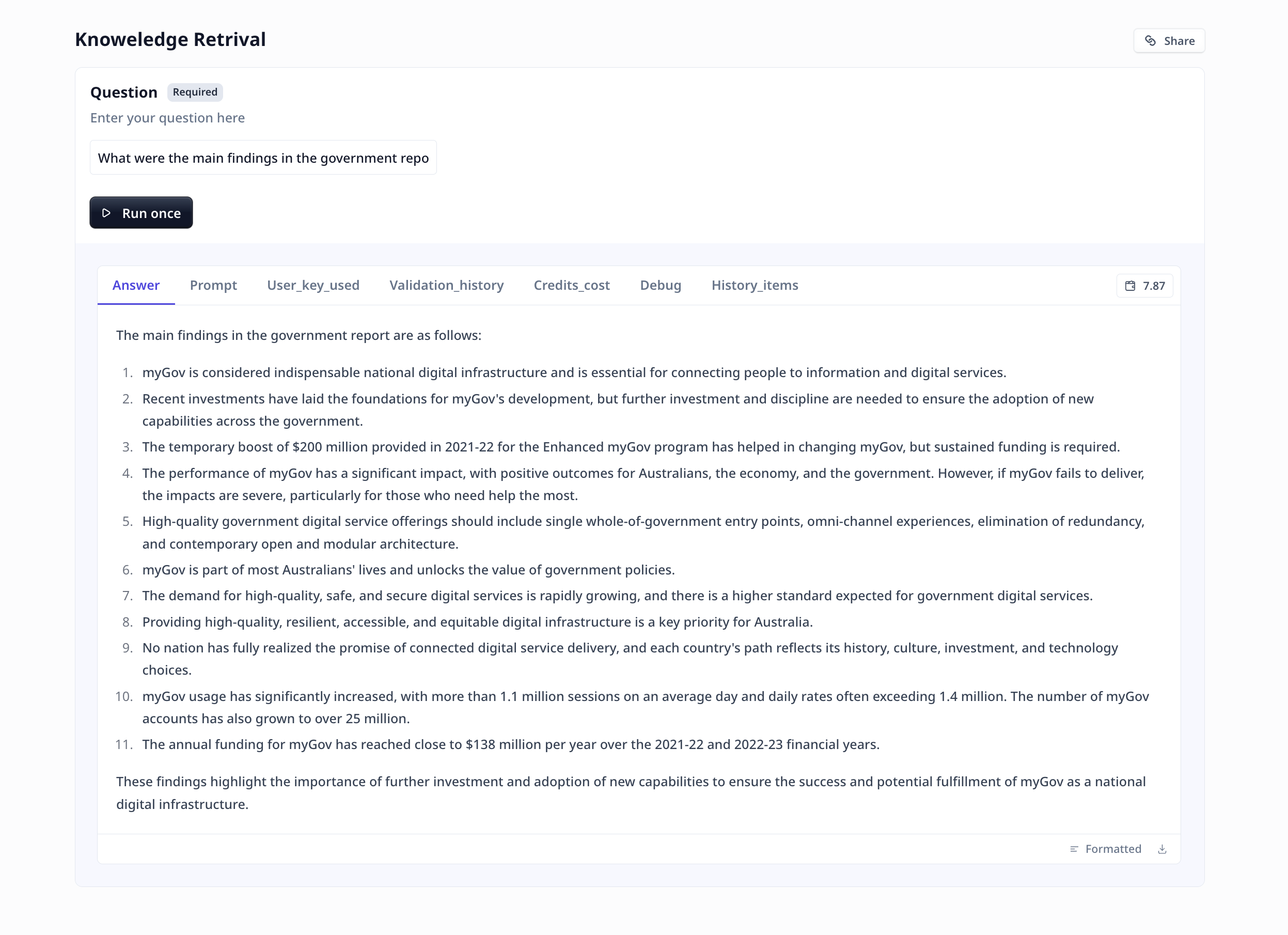
Was this page helpful?