Extract Website Content
Extract Website Content
There is a large amount of text data available on the net which can be an amazing source for tasks such as Q/A, research, and context generation. Relevance provides you with an easy-to-use component for scraping website contents
How to use the Extract website content step
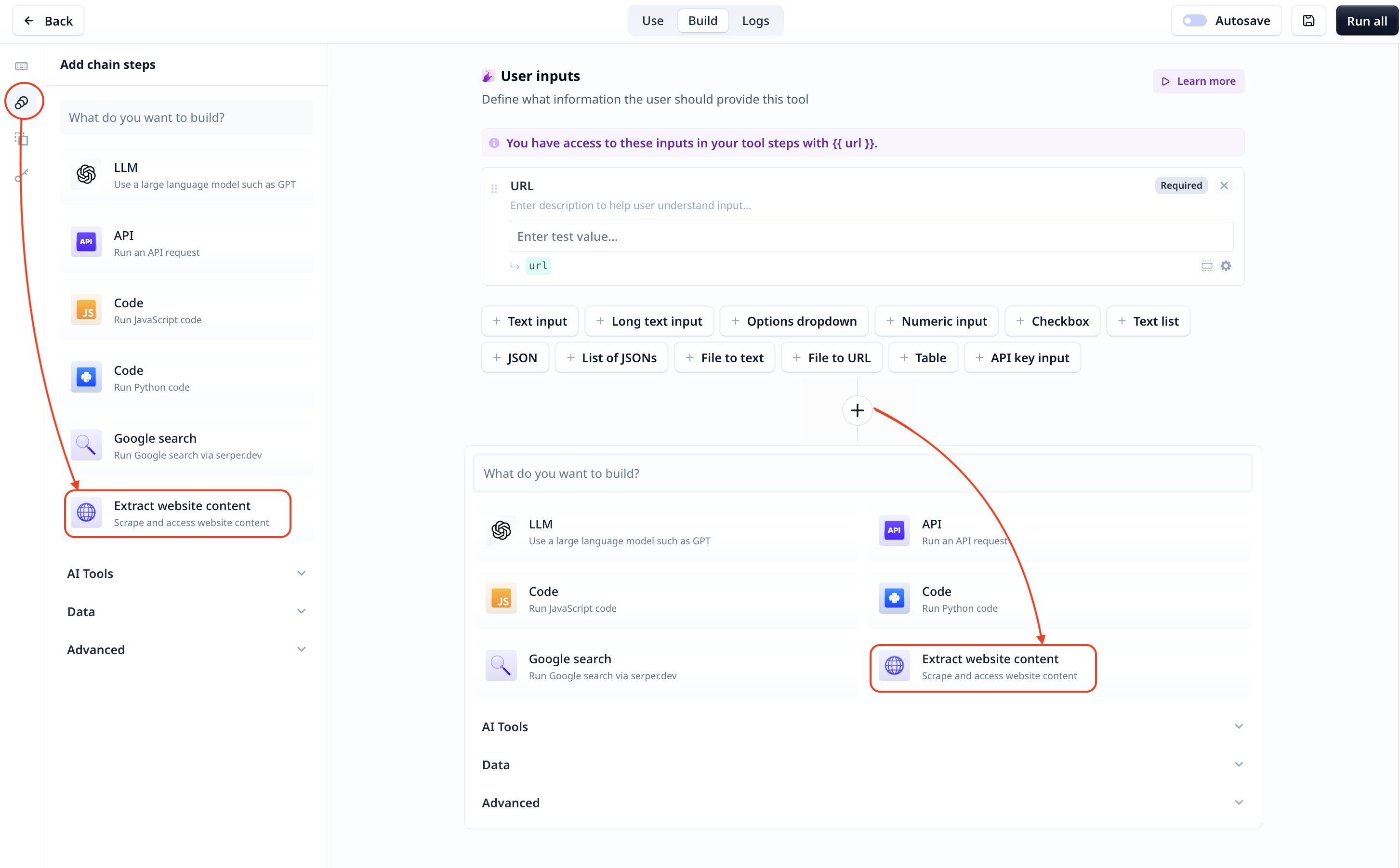
Add the component
You need to add the “Extract website content” step to your Tool (check how to get started with
creating a tool).
Website URL
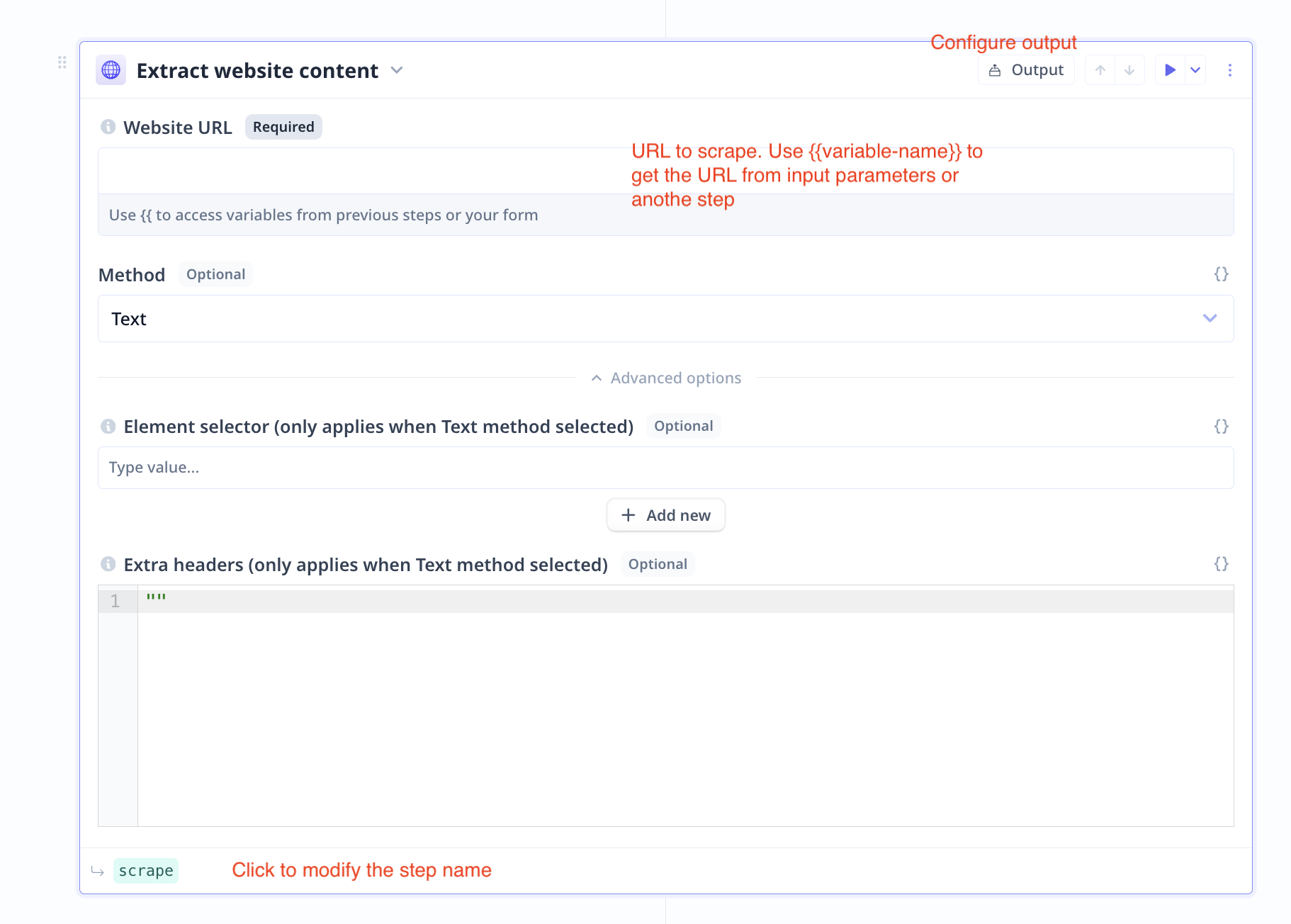
Directly enter a URL in the box or use the {{ to activate the variable mode. For instance, if the URL is in an input
component called my_url, use {{my_url}}. Or if the URL is the output of a Google-Search step, use {{google.organic[0].link}}
to access the url in the first search results (FAQ).
Method
You can specify if you wish to scrape data as Text or HTML. By default, Relevance scraps the Text.
Element Selector
You can specify which element from the HTML components to scrape. By default, it is set to body.
Note that using + Add new, you can specify a list of elements to be scrapped.
Extra headers
If you need to provide special information to be able to scrape a website, provide the data as a JSON object.
The below object shows an example where an authentication token called auth-token and a user-id are required.
{
"auth-token":"AUTHENTICATION-TOKEN",
"user-id":"USER-ID"
}
Follow the links below for more information about
- How to run a step
- How to delete a step
- How to configure output
- How to configure a default value
- How to move a step in a Tool
- How to duplicate a step
- How to add condition to a step (i.e. execute only if a condition is met)
- How to loop a step (i.e. run one step multiple times)
Access the step output
The output is a dictionary with two keys page and selectors containing the extracted text and if any selectors were used.
Below you can see samples where the default name assigned to the step scrape is used.
Note that a step name is different from the step title. Step titles can be found on the top left
of steps. A step name is shown on the bottom left, in smaller font and highlighted green.
scrape.output.page
scrape.output.selectors
Common errors
Wrong URL formatting
This error occurs when the URL field is set to a value that is not of type string. When using the output of another step make sure, you access the URL field. Read more at URL must be a string.
Non-array Elements
When setting up specific elements to be scrapped, make sure to use + Add new to have more than one Element. And if the
button is clicked do not leave it as an empty list. Use the x icon to the right of the row to remove the extra line.
Studio transformation browserless_scrape input validation error: must be array {"type":"array"} /element_selector
Invalid URL
This error occurs when the provided URL is not valid.
Protocol error (Page.navigate): Cannot navigate to invalid URL
Network issue
This error normally occurs when there are network issues. Make sure your connection is strong, refresh the page and try again.
Navigation failed because browser has disconnected!
Time output
This happens wh
Navigation timeout of 30000 ms exceeded
Was this page helpful?